





Muy interesante.
Nada que ver, pero me recuerda a la pelicula Minority Report, donde para predecir el futuro crimen utilizaba a tres personas, hermanos, para "visualizar" el futuro.
Por otro lado, estoy intentando loguearme en el sitio de deepseek con la cuenta de google y me salta error, que hay un problema con google :s:
DeepSeek y la caída de las acciones de NVidia

¿Por qué la aparición de DeepSeek en el mercado afectaría los valores de las acciones de NVidia y toda la industria?
La semana pasada apareció en escena una nueva empresa con un nuevo modelo, uno diría "uno más", pero DeepSeek no es "uno más" por un par de razones: es más potente en muchos aspectos que los mejores del mercado, es Open Source y gratuito y... el costo de entrenamiento resultó ser una ínfima fracción de lo que han gastado sus rivales.
¿Cambiará la industria? Por supuesto! Si esto cambia a cada mes...
Costo de entrenamiento
Una de las particularidades del entrenamiento de modelos de AI es la enorme cantidad de cómputo que se necesita para lograrlo.
Los modelos buscan abarcar todos los temas posibles, se entrenan con alta precisión de 32 bits, esto obliga al uso de enormes placas de video como la NVidia H100 que cuesta alrededor de USD 40.000 cada una.
Empresas como OpenAI, Anthropic, Meta o Amazon tienen decenas de miles de estas placas de video en sus datacenters. Eso es mucho dinero junto, la mayoría sin uso en el día a día hasta que luego hay que usarlas para entrenar otra versión.
Ahora multipliquen ese poder por la energía que hay que usar para alimentarlos, luego tomen cualquier modelo de 400 billones de parámetros y cárguenlo en gigas y gigas de RAM que nadie tiene en su casa.
Cada vez que usamos ChatGPT o Claude estamos apelando a esos racks de servidores llenos de placas que no podríamos pagar. Todas cargando un modelo gigante que puede resolver millones de diversos pedidos.
Desde DeepSeek se preguntaron ¿Cómo puedo hacer todo eso mucho más barato?
"DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training."
No es que, como muchos quieren creer, en China no se consigan las placas de video de NVidia por el bloqueo de AI que hay vigente, se consiguen, pero más fácil todavía es conseguir placas de video para jugar, las mismas que cualquiera de nosotros puede adquirir.
Para lograr la máxima eficiencia y el coste más barato desarmaron el problema en partes, literalmente.
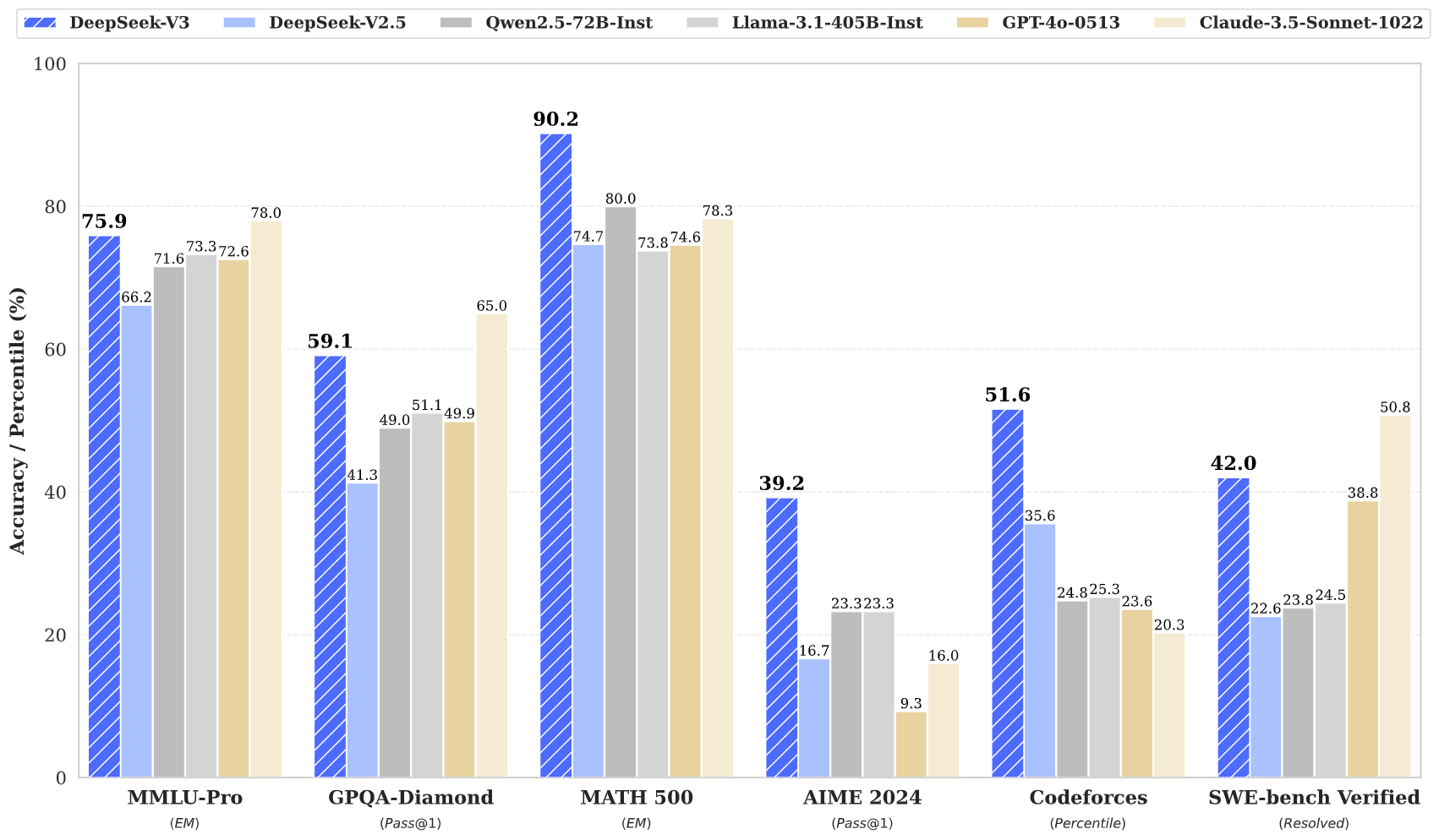
Cortando el problema en partes
A diferencia del resto de los modelos como GPT-4 o Claude 3.5 o Llama, DeepSeek tiene un formato diferente para los problemas.
Podemos considerar a los modelos "tradicionales" (exagerado hablar de tradición acá![]() como modelos monolíticos, un gran archivo con TODO el conocimiento en uno.
como modelos monolíticos, un gran archivo con TODO el conocimiento en uno.
Esto equivale a una sola persona sabiendo de todos los temas del unvierso. En cambio DeepSeek está armado de a partes, como si fuesen diez especialistas en distintos temas.
De los 671 billones de parámetros sólo están activos 37B por instancia de pensamiento, es decir, como si le preguntaran al especialista de tal o cual tema.
Segundo, y no menos importante, pasar la precisión de FP32 a FP8, no sólo las placas comerciales son mejores en esto, es mucho más barato.
Recortar tantos ceros en un valor (los decimales que se le sacan de precisión) podrían hacer al modelo más "tonto", pero ¿Cuánto se pierde? El modelo pasa a ser un 90% igual de inteligente, se pierde muy poco, esa precisión se puede suplir con mejor razonamiento y más velocidad.
Entonces al bajar la precisión y dividir el problema en partes DeepSeek necesita sólo una fracción de memoria y GPU.
Un detalle no menor, cuando se tiene un modelo gigante el tamaño del problema a resolver evoluciona en la memoria de forma exponencial, cada token se multiplica en múltiples dimensiones. Resolver una simple pregunta va creciendo hasta agotar la memoria muy rápido.
Esto se nota cuando tenemos una conversación larga con un modelo y en un momento dado empieza a delirar.
Con este otro enfoque de DeepSeek ese crecimiento exponencial es mucho menor (lo he podido corroborar con LM Studio en modo local).
Acciones y caídas
El golpe para NVidia es, en realidad, una combinación de factores. Por un lado el precio de la acción estaba muy alto, una empresa que de cada placa que vende gana el 90% del precio, obviamente está juntando el dinero en pala y todos quieren una tajada. Eso hace que la acción vuele y se cotice mucho más alto que ninguna otra.
Pero todo lo que sube debe bajar.
La aparición de DeepSeek le pone un freno a semejante expansión. No porque HOY vaya a cambiar algo, sino porque esas otras empresas como OpenAI, Meta y Anthropic van a copiar a DeepSeek para abaratar los costos y acelerar la producción.
El enfoque de menor precisión y el de subdividir la acción del modelo es una solución genial a un presupuesto bajo, pero como DeepSeek es de código libre y con papers explicando todo lo que han hecho, todas las otras empresas van a analizar y posiblemente implementar su propia versión de la idea.
Esto implica que la aceleración de ventas de GPUs de alto nivel puede frenarse bastante, no es que NVidia se va a fundir, simplemente se va a acomodar en el valor que se hace más honesto con la realidad.
En vez de 10.000 GPUs vas a necesitar la mitad o menos, en vez de estar entrenando un mega-modelo durante semanas, lo vas a poder tener en una, el costo de uso de la API baja un 95% porque el uso en tiempo real de GPU es muy inferior. El hecho de que funcione en una placa gamer le mete mucha presión a NVidia y sus precios.
Cabe destacar que Liang Wenfeng, el fundador de DeepSeek, es conocido por haber estado coleccionando GPUs A100 de NVidia por todo el mundo antes del bloqueo que estableció Joe Biden a la exportación a China de ese tipo de equipos.
Aun así, en vez de tirarle GPUs y dinero al problema, los de DeepSeek buscaron cómo resolverlo con ingenio, y lo lograron, esto va a impulsar a toda la industria en ese camino, no es que sea una revolución, es la evolución que cada año tenemos.
Lo interesante del mundo de la AI es que no hay líderes por mucho tiempo, va mutando, va cambiando, mañana sale un modelo por ahí, otro por allá, algunos mueren, otros resuelven problemas de forma genial.
PS: El gobierno Chino. Esto es interesante, DeepSeek R1 es un modelo con condicionamiento del gobierno chino, todo lo que hagan en el sitio de ellos será logueado, no es esto ningún problema, simplemente para que lo sepan ¿Lo bueno? Pueden ejecutar el modelo sin que el gobierno de ese país se entere de forma local, hay versión pequeña en LMStudio para descargar.
Si te gustó esta nota podés...

Categoría: Tecnología
Etiquetas: ai china costo deepseek entrenamiento gpu ia inteligencia artificial modelos negocios nvidia open source procesador
Otros posts que podrían llegar a gustarte...
Comentarios
-
Desde que me compré la impresora 3D hace casi 6 meses dejé de lado todo lo que es IA y ya me siento un campesino que no entiende cómo es que hay una autopista donde hace un mes había un camino de tierra. Pestañeás y te llevan puesto, qué los tiró.
-
en términos generales no te perdiste de tanto y está bueno "oxigenar" para volver cuando hay novedades superlativas, el único problema de no enterarte de las cosas nuevas es quedarse encerrado en algo viejo, ej: usar Dall-E para hacer imágenes, se ven obsoletas, o usar ChatGPT 3 por ejemplo, son cosas que nadie haría si conociera las opciones actuales.
En un año no tengo idea qué vamos a estar usando ni cual será la novedad, es vertiginoso.
PS: ah, el otro día leí de una empresa que le quiso poner suscripción para imprimir a sus 3D y se le armó un quilombo terrible, no podés Epsonizar/HPizar una impresora 3D, perdés mal
-
Hace un año las acciones de Nvidia estaban a 60usd, hoy (incluyendo la baja) están a 140. Un x2.3 del valor, en dólares en un año!. Seguro no van a seguir subiendo a esa tasa hasta que no haya otra innovación, pero realmente no es que nadie esté perdiendo dinero ahi creo yo.
-
La aceleración de estos últimos 3 años en cuanto a poder de cómputo ha sido abrumadora. Si bien no es tecnología nueva, el avance en cuanto a potencia de cálculo y proceso, hizo que, cosas que demoraban meses o años, se hagan en segundos. Esa reducción de tiempo, aplicada a la velocidsd de avance, hace que en muy poco tiempo, todo cambie y evolucione exageradamente rápido.
Lo que no evoluciona a ese ritmo es la capacidad de control sobre estos avances. Los ingenieros son del modelo "si uno anda, pongamos 1000 en paralelo y tiene que volar" y veamos que sale. Y ese es el problema. Chocar a 10 o a 10.000 no deja de ser un choque, pero a mas velocidad, peores consecuencias.
Esperemos prime la cordura y sepan manejar las innovaciones. Y que aprender no sea estrolándose a 10.000
-
tomas
27/01/2025 - 19:16:48
Recién hoy me termina de cerrar que buscaban los chinos.
Hace años existe una colaboración entre la FAMAF-UNC y un instituto Chino, y de vez en cuando llegan invitaciones. IA, ciencia de datos. Hay argentinos allí.
Que diferencia, los chinos pagan todo, mientras los norteamericanos levantan el muro. Se nota la desesperación.
-
Saturno
28/01/2025 - 22:09:03
Osea, cortarle el chorro de placas nvidia de alto rendimiento hizo que los chinos agudizaran el ingenio para lograr lo mismo con placas mas "baratas".
-
no, es mejor, los obligó a pensar en OTRA forma de hacerlo que ahora va a moverle el piso a todal la industria
-
Nvidia no es la primera vez que busca monopolizar/cautivar un mercado. Son bastante agresivos. De hecho, nunca liberaron sus drivers (para linux) porque, justamente, limitan las posibilidades de sus chips por software. Cualquier GPU podría usarse para render/cálculo por fuera de solo para video, pero, por soft, esto esta limitado. Incluso hay modelos idénticos que vienen limitados para así tener una gama baja (si buscan,hay gente que modea las placas para romper con este bloqueo)
Hay que reconocer que los chinos, con esto, les patearon el tablero.
-
Me encanta todo lo que se generó con este nuevo player en la escena y coincido con lo que decís en un comentario: "En un año no tengo idea qué vamos a estar usando ni cual será la novedad, es vertiginoso."